
Llama 3 Chat Template
Llama 3 Chat Template - The meta llama 3.3 multilingual large language model (llm) is a pretrained and instruction tuned generative model in 70b (text in/text out). It signals the end of the { {assistant_message}} by generating the <|eot_id|>. Chatml is simple, it's just this: This page covers capabilities and guidance specific to the models released with llama 3.2: Reload to refresh your session. The llama 3.3 instruction tuned. Reload to refresh your session.
You signed out in another tab or window. It signals the end of the { {assistant_message}} by generating the <|eot_id|>. The llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Reload to refresh your session.
When you receive a tool call response, use the output to format an answer to the orginal. In this tutorial, we’ll cover what you need to know to get you quickly started on preparing your own custom. You signed out in another tab or window. The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the llama. The meta llama 3.3 multilingual large language model (llm) is a pretrained and instruction tuned generative model in 70b (text in/text out). This was built with the new `@huggingface/jinja` library, which is a minimalistic javascript implementation of the jinja templating engine, specifically designed for parsing + rendering.
blackhole33/llamachat_template_10000sample · Hugging Face

This page covers capabilities and guidance specific to the models released with llama 3.2: Explore the vllm llama 3 chat template, designed for efficient interactions and enhanced user experience. This new chat template adds proper.
Heather Hale Headline Llama 2 Chat Api

In this tutorial, we’ll cover what you need to know to get you quickly started on preparing your own custom. The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the llama..
llama3chatqa

This new chat template adds proper support for tool calling, and also fixes issues with missing support for add_generation_prompt. Reload to refresh your session. In our code, the messages are stored as a std::vector named.
Llama 3 by Meta Revolutionizing the Landscape of AI Fusion Chat

It signals the end of the { {assistant_message}} by generating the <|eot_id|>. You signed in with another tab or window. This page covers capabilities and guidance specific to the models released with llama 3.2: The.
llama3text

The meta llama 3.3 multilingual large language model (llm) is a pretrained and instruction tuned generative model in 70b (text in/text out). Explore the vllm llama 3 chat template, designed for efficient interactions and enhanced.
antareepdey/Medical_chat_Llamachattemplate · Datasets at Hugging Face

When you receive a tool call response, use the output to format an answer to the orginal. The llama 3.3 instruction tuned. This page covers capabilities and guidance specific to the models released with llama.
Decoding Llama3 Part 1 Intro to Llama3 Decoding Llama3 An
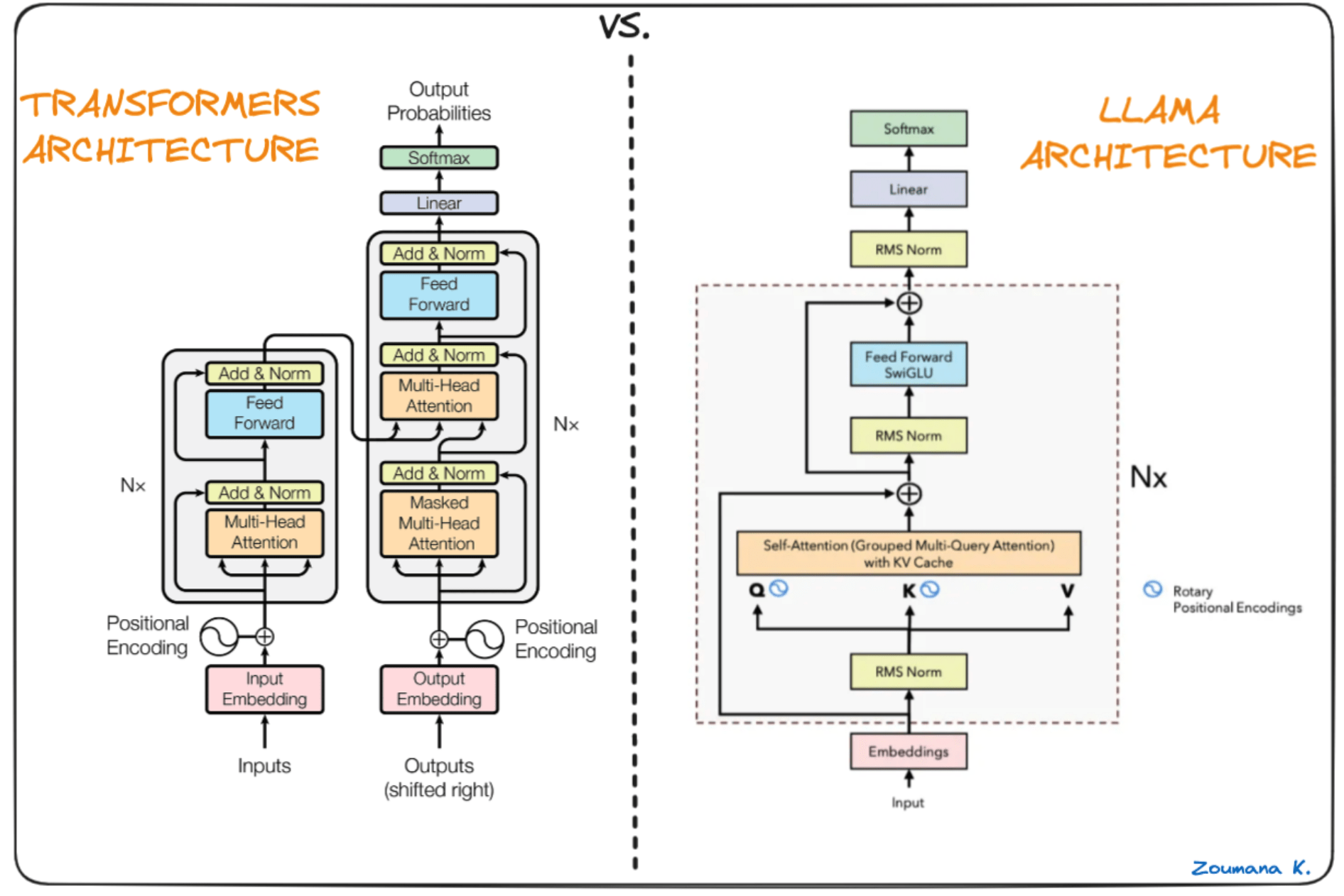
Reload to refresh your session. Chatml is simple, it's just this: You switched accounts on another tab. The meta llama 3.3 multilingual large language model (llm) is a pretrained and instruction tuned generative model in.
wangrice/ft_llama_chat_template · Hugging Face

The llama 3.3 instruction tuned. This new chat template adds proper support for tool calling, and also fixes issues with missing support for add_generation_prompt. When you receive a tool call response, use the output to.
LLaMA 2 Every Resource you need

This page covers capabilities and guidance specific to the models released with llama 3.2: This was built with the new `@huggingface/jinja` library, which is a minimalistic javascript implementation of the jinja templating engine, specifically designed.
The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the llama. In our code, the messages are stored as a std::vector named _messages where llama_chat_message is a. You signed in with another tab or window. This was built with the new `@huggingface/jinja` library, which is a minimalistic javascript implementation of the jinja templating engine, specifically designed for parsing + rendering. Reload to refresh your session.
You signed in with another tab or window. The llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. The meta llama 3.3 multilingual large language model (llm) is a pretrained and instruction tuned generative model in 70b (text in/text out). You switched accounts on another tab.
The System Prompt Is The First Message Of The Conversation.
Chatml is simple, it's just this: It signals the end of the { {assistant_message}} by generating the <|eot_id|>. Explore the vllm llama 3 chat template, designed for efficient interactions and enhanced user experience. Changes to the prompt format.
You Signed Out In Another Tab Or Window.
Reload to refresh your session. The meta llama 3.3 multilingual large language model (llm) is a pretrained and instruction tuned generative model in 70b (text in/text out). In our code, the messages are stored as a std::vector named _messages where llama_chat_message is a. You switched accounts on another tab.
You Signed In With Another Tab Or Window.
This new chat template adds proper support for tool calling, and also fixes issues with missing support for add_generation_prompt. This page covers capabilities and guidance specific to the models released with llama 3.2: Following this prompt, llama 3 completes it by generating the { {assistant_message}}. The llama 3.3 instruction tuned.
For Many Cases Where An Application Is Using A Hugging Face (Hf) Variant Of The Llama 3 Model, The Upgrade Path To Llama 3.1 Should Be Straightforward.
In this tutorial, we’ll cover what you need to know to get you quickly started on preparing your own custom. The llama 3.2 quantized models (1b/3b), the llama 3.2 lightweight models (1b/3b) and the llama. Reload to refresh your session. When you receive a tool call response, use the output to format an answer to the orginal.
You signed in with another tab or window. Find out how to use, fine. The system prompt is the first message of the conversation. This new chat template adds proper support for tool calling, and also fixes issues with missing support for add_generation_prompt. Reload to refresh your session.